Basics of CI/CD using Gitlab
GitLab offers a unique opportunity to have both a free private repository and free CI/CD out of the box in one place. To maintain balance, it is configured in a no less unique way through a configuration file, which is not so easy to understand (I spent way too long figuring it out the first time). Eventually, I got the hang of it, and I want to share my experience.
How does all this work?
There is a .gitlab-ci.yml file located in the root of the project, where all the build magic is configured. If GitLab detects that there is such a file in the branch, it triggers a build based on the algorithm described in this file.
By default, builds are triggered on every push to the branch.
This means that if one branch doesn’t have a config, but two other branches have fundamentally different configs, and you push something new to all three branches simultaneously, two builds with different algorithms will be triggered.
You can’t configure builds without this file, unlike in TeamCity or Jenkins.
Yay, I want to host my FE-project on gitlab!
Unlike simple GitHub Pages, where you build whatever you want and just push the index.html file to the repository, you can't do that here. Well, theoretically, you could, but nothing would work automatically.
How would a GitLab config look for something “like on GitHub Pages” (I’m assuming, just like with GitHub Pages, we’ve already built everything into a dist folder and pushed it)?
The key secret to deploying static content is to put everything necessary into the public folder and mark it as an artifact.
At this point, you might wonder — why build everything locally if you can do it on GitLab’s machines, especially since you’re already writing the config? It will take a bit more time, but it will be more reliable.
We’ve figured out how to make the site build and deploy — it’s enough to just make changes, push them, and it will automatically rebuild and update!
Now we can dive deeper into the config and think about what other possibilities we can utilize.
Stages of the pipeline
Let’s break down what this is and how to use it effectively. If you think about it, there really are three main stages when working with code: build, test (to make sure it’s ready for deployment), and deploy. If one of these stages fails, there’s no need to run the others.
Following this principle, GitLab operates with:
- Jobs: There can be many different jobs. Each one does its own small task — builds the frontend with one parameter, builds it with another, runs interface tests, runs the backend linter.
- Stages: These are the build stages. Within the same stage, all jobs are executed without a specific order. However, by default, jobs from the next stage do not start until all jobs from the previous stage have successfully completed.
- Pipelines: A pipeline is created every time you push or if you trigger it manually. One pipeline is a single build with a specific configuration of stages and jobs.
The peculiarity of GitLab’s config is that we don’t follow the seemingly logical approach of declaring stages and then filling them with tasks. Instead, we assign each task to a specific stage. Of course, you can create any stages you want, not just the standard ones.
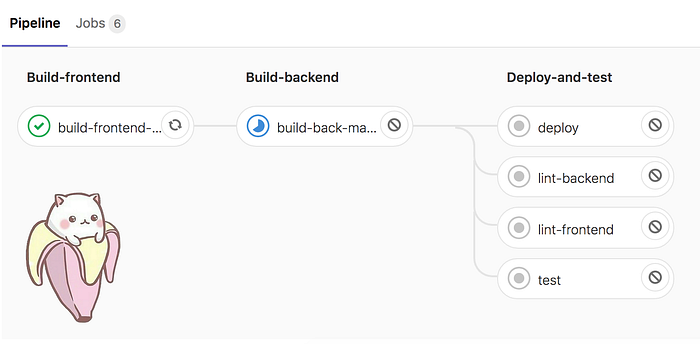
For example, piece of config corresponding to the screenshot above:
stages:
- build-frontend
- build-backend
- deploy-and-testbuild-frontend-prod:
stage: build-frontend
script:
- npm run build:prodtest:
stage: deploy-and-test
script:
- npm test
If you change the order of the stages in the config, they will start executing in a different order.
cache
Builds usually take longer than we’d like. The first thing that comes to mind is: do we really need to download dependencies every time? This can be improved!
In the task config, you just need to add something like this:
pages:
cache:
key: cache-for-my-task-${CI_COMMIT_REF_SLUG}
paths:
- node_modules${CI_COMMIT_REF_SLUG} is an environment variable created by GitLab. It stores a hash of the branch name in which the process is running.
Here’s how it works: each time a task is triggered, GitLab will look for a cached version with a name matching cache-for-my-task-branch_hash. If it finds one, it will download and add it to the codebase on which further actions will be performed.
In this case, it will download all node_modules saved from the previous run, and after performing the standard npm i step, the installation of dependencies will happen much faster.
GitLab provides many different variables that can be used here. Caching node_modules is most effective by branches, although you can share the cache across the entire repository. You can even write a clever condition to handle it.
Artifacts
In the config above you can find:
artifacts:
paths:
- publicArtifacts work like this: files located in the specified paths are uploaded to the GitLab server at the end of each job and downloaded at the start of each job in the next stage.
Wait, that sounds like caching! What’s the difference?
Cache, as the name suggests, is used to temporarily store something to speed up the build process. By design, GitLab does not guarantee that the cache will always be available — it can be lost.
- With the cache, we can specify a key, but with artifacts, we cannot. This is because the cache is shared between multiple pipelines — you can run the build for a branch twice, and they will use the same cache (since the branch name we reference in the key is the same)
- Artifacts, on the other hand, live only within a single pipeline and are passed only from stage to stage, not between jobs within the same stage.
- Additionally, an artifact can be downloaded from the GitLab interface — it is packed into a zip file and is available for download and analysis (which is convenient for debugging issues with
node_modules). The cache doesn’t have this option. On a deeper level, the cache is stored where the runner is set up, while artifacts are stored on GitLab itself. This is what ensures the presence or absence of caches and artifacts. You can also configure artifacts to be stored for up to 30 days.
I’ve described two major differences, and there are a few more that you can find here. But the question remains: how does adding artifacts enable deploying GitLab Pages, and when should they be used at all?
- GitLab Pages deployment happens simply because GitLab has designed it that way — if the
publicfolder is included as an artifact, it’s used to serve static files. That’s the entire trick - Artfacts should be used when you need to pass data between build stages. For example, in one stage, you build the frontend bundle, and then pass it as an artifact to the deployment stage.
Now you know the basic principles of CD on GitLab, and you can host and deploy code secretly from your GitHub followers (and if you don’t want to expose GitLab either, private repositories plus Heroku are a great help!).
P.S. If you have any questions or think I should write a few more articles about GitLab, I look forward to your comments!
